I recently randomly wandered onto the Mastodon admin page. What I saw there will shock you.
(I’m so sorry about that introduction)

That’s perhaps a bit much in the Media storage area for a single user instance.
I was pretty sure that I had previously configured Mastodon’s media cache retention to 7 days. Checking up on that, I found that I had remembered correctly.
So I dug a bit deeper, and it turns out that the Vacuum failed. If you’d like
to check in your own logs, search the Sidekiq logs for Vacuum:
2024-09-01T05:35:00.024Z pid=7 tid=3dwb INFO: queueing Scheduler::VacuumScheduler (vacuum_scheduler)
E, [2024-09-01T05:35:15.395684 #7] ERROR -- : Error while running Vacuum::MediaAttachmentsVacuum: Net::ReadTimeout with #<TCPSocket:(closed)>
2024-09-01T05:36:49.666Z pid=7 tid=1bhhb class=Scheduler::VacuumScheduler jid=eb78e67fb9d775c1cac1e187 elapsed=109.631 INFO: done
These log lines repeated every day. There hasn’t been a single successful run in months, leading to 477 GB of media files. After some googling, I ended up with the idea that this might be due to the batch size that Mastodon uses by default for these delete requests to S3. So I reduced it to 100, from the default 1000.
This also failed, with the same log output. So I decided to look a bit closer at my media storage, which is in an S3 bucket on my Homelab’s Ceph storage cluster. Looking at the RGW S3 daemons in my cluster, I found these log lines:
2024-10-19T03:32:31.269+0000 7f825e354700 1 ====== starting new request req=0x7f8161159660 =====
2024-10-19T03:32:36.273+0000 7f8166965700 1 req 1601675399780187004 5.004083157s op->ERRORHANDLER: err_no=-2 new_err_no=-2
2024-10-19T03:32:36.273+0000 7f8166965700 1 ====== req done req=0x7f8161159660 op status=-2 http_status=404 latency=5.004083157s ======
2024-10-19T03:32:36.273+0000 7f8166965700 1 beast: 0x7f8161159660: 260.0.0.10 - mastodon [19/Oct/2024:03:32:31.269 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=5.004083157s
And many more like them.
Detour: Mastodon media cache cleanup implementation
Let’s do a short detour and look at what exactly this vacuum job does with S3 based storage. The interesting part of the code can be found in the app/lib/attachment_batch.rb file. The relevant part for this discussion is this one:
# We can batch deletes over S3, but there is a limit of how many
# objects can be processed at once, so we have to potentially
# separate them into multiple calls.
retries = 0
keys.each_slice(LIMIT) do |keys_slice|
logger.debug { "Deleting #{keys_slice.size} objects" }
bucket.delete_objects(delete: {
objects: keys_slice.map { |key| { key: key } },
quiet: true,
})
rescue => e
retries += 1
if retries < MAX_RETRY
logger.debug "Retry #{retries}/#{MAX_RETRY} after #{e.message}"
sleep 2**retries
retry
else
logger.error "Batch deletion from S3 failed after #{e.message}"
raise e
end
end
What happens here is Mastodon using the DeleteObjects S3 API. With this API, you don’t delete one object per request, but instead send over an XML document with all of the paths to be deleted in a single request.
The size of the batches is configurable with the S3_BATCH_DELETE_LIMIT variable.
The number of retries for a failed delete can be set in turn with S3_BATCH_DELETE_RETRY.
Trial and error
Looking more closely at those log lines, I found specifically the last one pretty interesting:
2024-10-19T03:32:36.273+0000 7f8166965700 1 beast: 0x7f8161159660: 10.86.5.129 - mastodon [19/Oct/2024:03:32:31.269 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=5.004083157s
Namely that the latency is given as (almost) 5 seconds. Triggering the vacuum job several more times, I found that the latency stayed the same: Around 5 seconds for every failed request. At the same time, Mastodon’s logs were talking about a read timeout:
E, [2024-09-01T05:35:15.395684 #7] ERROR -- : Error while running Vacuum::MediaAttachmentsVacuum: Net::ReadTimeout with #<TCPSocket:(closed)>
So looking around a bit, I found the S3_READ_TIMEOUT variable in Mastodon.
Default: 5 (seconds)
The number of seconds before the HTTP handler should timeout while waiting for an HTTP response.
That default of 5 seconds fits the 5 second latency from the S3 RadosGW logs perfectly. So I increased that value to 600 seconds. Because honestly, I didn’t really care how long it took, as long as it finished before the next run of the Vacuum job.
But this was also unsuccessful, with RadosGW timing out the request this time around.
I then decided to turn to the tootctl tool’s media remove
command, with the following invocation at first:
tootctl media remove --days 7
And this worked like a charm. I mean, almost. It crashed the Sidekiq container I ran it in several times via OOM, until I created a separate container and provided it with 4 GB of RAM. The effect of those invocations can be seen in the post’s cover image. I initially deleted about 150k objects, followed by another whopping 900k objects. Note: These are RADOS objects in the Ceph cluster, which do not necessarily have a 1:1 relationship to S3 objects. But still. My Mastodon media cache accidentally took up pretty much 50% of my cluster’s overall RADOS objects at that time. And that cluster also houses my considerable media collection, digitized documents, podcasts and so on and so forth.

The object change graph of my Ceph cluster. It clearly shows that it can easily handle about 1k deletes per minute.
The above graph shows the problem: My Ceph cluster can easily delete almost 1k objects per minute. That it should take five seconds to delete 100 and, in a later test, 10, is ridiculous.
The big difference between tootctl media remove and what the Vacuum job does
lies in which S3 APIs they use. As I’ve mentioned above, the Vacuum job uses
the DeleteObjects API and runs into some sort of issue, running into Masto’s
read timeout.
tootctl media remove, on the other hand, sends DELETE requests:
2024-10-19T18:32:55.170+0000 7fa90b9df700 1 ====== starting new request req=0x7fa9c4a52660 =====
2024-10-19T18:32:55.178+0000 7fa90b9df700 1 ====== req done req=0x7fa9c4a52660 op status=0 http_status=200 latency=0.008000003s ======
2024-10-19T18:32:55.178+0000 7fa90b9df700 1 beast: 0x7fa9c4a52660: 260.0.0.10 - mastodon [19/Oct/2024:18:32:55.170 +0000] "HEAD /mastodon/cache/media_attachments/files/111/526/742/001/415/010/small/d73862fc1c5188e0.jpg HTTP/1.1" 200 0 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,B,N" - latency=0.008000003s
2024-10-19T18:32:55.190+0000 7fa8968f5700 1 ====== starting new request req=0x7fa9c4a52660 =====
2024-10-19T18:32:55.246+0000 7fa935232700 1 ====== req done req=0x7fa9c4a52660 op status=0 http_status=204 latency=0.056000017s ======
2024-10-19T18:32:55.246+0000 7fa935232700 1 beast: 0x7fa9c4a52660: 260.0.0.10 - mastodon [19/Oct/2024:18:32:55.190 +0000] "DELETE /mastodon/cache/media_attachments/files/111/526/742/001/415/010/original/d73862fc1c5188e0.jpg HTTP/1.1" 204 0 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=0.056000017s
Interestingly, if I take the latency of that delete - 0.5 seconds, times 100 requests, I end up with the problematic 5 second S3 read timeout the Vacuum job is hitting. But sadly, this is not the problem. Because I also tried the Vacuum job with a batch size of 10 and got the same results. Which is ridiculous, as the graph above shows: The cluster can indeed handle roughly 1k requests per minute.
Next, I decided to reduce the batch size to 1 and increase the S3_READ_TIMEOUT
to 60 seconds. With that, I got a mix of results, which is even weirder. First
of all, I had not a single failure in the large number of DELETE requests that
tootctl media remove send, and I wasn’t doing anything really different here -
just using a different API. But the results were still a mix of 404 after the
60 second read timeout, and successful runs:
2024-10-26T07:22:09.199+0000 7fb404aae700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:07:22:08.123 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.076018214s
2024-10-26T07:23:59.137+0000 7fb404aae700 1 beast: 0x7fb3ce13e660: 260.0.0.10 - mastodon [26/Oct/2024:07:23:58.053 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.084018350s
2024-10-26T07:33:02.526+0000 7fb479397700 1 beast: 0x7fb3ce03c660: 260.0.0.10 - mastodon [26/Oct/2024:07:32:02.453 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.073013306s
2024-10-26T07:34:04.623+0000 7fb426af2700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:07:33:04.562 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.061012268s
2024-10-26T07:35:08.732+0000 7fb427af4700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:07:34:08.671 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.061012268s
2024-10-26T07:36:16.833+0000 7fb3e426d700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:07:35:16.772 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.061012268s
2024-10-26T07:37:32.930+0000 7fb48e3c1700 1 beast: 0x7fb3ce1bf660: 260.0.0.10 - mastodon [26/Oct/2024:07:36:32.873 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.057010651s
2024-10-26T07:41:09.146+0000 7fb430305700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:07:40:09.093 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.053012848s
2024-10-26T07:44:17.253+0000 7fb44eb42700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:07:43:17.196 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.057010651s
2024-10-26T07:49:33.370+0000 7fb4b2c0a700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:07:48:33.305 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.065013885s
2024-10-26T08:00:06.441+0000 7fb4202e5700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:07:59:06.396 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.044975281s
2024-10-26T08:03:20.760+0000 7fb4963d1700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:02:20.711 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.048984528s
2024-10-26T08:04:36.873+0000 7fb4cdc40700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:03:36.812 +0000] "POST /mastodon?delete HTTP/1.1" 404 219 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=60.060985565s
2024-10-26T08:09:00.294+0000 7fb4042ad700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:08:59.246 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.048017383s
2024-10-26T08:12:22.101+0000 7fb404aae700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:12:21.033 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.068017721s
2024-10-26T08:13:15.786+0000 7fb404aae700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:13:14.742 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.044017315s
2024-10-26T08:15:44.468+0000 7fb4172d3700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:15:43.404 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.064017773s
2024-10-26T08:18:53.404+0000 7fb3dca5e700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:18:52.336 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.068017840s
2024-10-26T08:41:17.738+0000 7fb4042ad700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:41:16.690 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.048017621s
2024-10-26T08:47:17.448+0000 7fb41aada700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:47:16.404 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.044017553s
2024-10-26T08:50:33.055+0000 7fb4042ad700 1 beast: 0x7fb3ce240660: 260.0.0.10 - mastodon [26/Oct/2024:08:50:31.987 +0000] "POST /mastodon?delete HTTP/1.1" 200 137 - "aws-sdk-ruby3/3.209.0 ua/2.1 api/s3#1.166.0 os/linux md/aarch64 lang/ruby#3.3.5 md/3.3.5 m/A,N" - latency=1.068017960s
This result somehow makes even less sense than the previous ones. Why would deleting a single object per request sometimes take 60 seconds, and sometimes just 1 second? I had no idea whatsoever. But the result convinced me that Mastodon was likely not at fault here. There had to be some issue with my Ceph cluster’s RGW setup.
Digging deep
Thinking that the issue had to be in the Ceph RadosGW (the Ceph component providing an S3 API), I first increased the debug level to max and did some more delete attempts.
I enabled the debug logs in the RGW daemons with this command:
ceph config set client.rgw debug_rgw 20/5
This spits out a lot of debug logs. I shortened the logs below.
Here are the logs of a working one:
0.000000000s initializing for trans_id = tx000003cf3e5d2ed1c29cf-00671ccd8a-4445ad-homenet
0.000000000s rgw api priority: s3=8 s3website=7
0.000000000s host=s3.example.com
0.000000000s subdomain= domain= in_hosted_domain=0 in_hosted_domain_s3website=0
0.000000000s final domain/bucket subdomain= domain= in_hosted_domain=0 in_hosted_domain_s3website=0 s->info.domain= s->info.request_uri=/mastodon
[...]
0.004000068s s3:multi_object_delete reading permissions
0.004000068s s3:multi_object_delete init op
0.004000068s s3:multi_object_delete verifying op mask
0.004000068s s3:multi_object_delete required_mask= 4 user.op_mask=7
0.004000068s s3:multi_object_delete verifying op permissions
1.004017115s s3:multi_object_delete NOTICE: call to do_aws4_auth_completion
1.004017115s s3:multi_object_delete v4 auth ok -- do_aws4_auth_completion
1.004017115s s3:multi_object_delete NOTICE: call to do_aws4_auth_completion
1.004017115s s3:multi_object_delete -- Getting permissions begin with perm_mask=50
[...]
1.004017115s s3:multi_object_delete verifying op params
1.004017115s s3:multi_object_delete pre-executing
1.004017115s s3:multi_object_delete check rate limiting
1.004017115s s3:multi_object_delete executing
1.004017115s s3:multi_object_delete get_obj_state: rctx=0x7fb3ce13d9a0 obj=mastodon:cache/media_attachments/files/113/278/263/816/166/764/original/cf2d002b5ad122a0.png state=0x564633f22de8 s->prefetch_data=0
1.004017115s s3:multi_object_delete WARNING: blocking librados call
1.004017115s s3:multi_object_delete manifest: total_size = 302601
1.004017115s s3:multi_object_delete get_obj_state: setting s->obj_tag to 87393fd3-1c76-49fc-bed3-c132da8963ec.4434159.8185423419560928886
1.004017115s s3:multi_object_delete get_obj_state: rctx=0x7fb3ce13d9a0 obj=mastodon:cache/media_attachments/files/113/278/263/816/166/764/original/cf2d002b5ad122a0.png state=0x564633f22de8 s->prefetch_data=0
1.004017115s s3:multi_object_delete get_obj_state: rctx=0x7fb3ce13d9a0 obj=mastodon:cache/media_attachments/files/113/278/263/816/166/764/original/cf2d002b5ad122a0.png state=0x564633f22de8 s->prefetch_data=0
1.004017115s s3:multi_object_delete bucket index object: homenet.rgw.buckets.index:.dir.87393fd3-1c76-49fc-bed3-c132da8963ec.4314167.1.16
1.016017318s s3:multi_object_delete WARNING: blocking librados call
1.044017792s s3:multi_object_delete cache get: name=homenet.rgw.log++bucket.sync-source-hints.mastodon : hit (negative entry)
1.044017792s s3:multi_object_delete cache get: name=homenet.rgw.log++bucket.sync-target-hints.mastodon : hit (negative entry)
1.044017792s s3:multi_object_delete chain_cache_entry: cache_locator=
1.044017792s s3:multi_object_delete chain_cache_entry: couldn't find cache locator
1.044017792s s3:multi_object_delete couldn't put bucket_sync_policy cache entry, might have raced with data changes
1.044017792s s3:multi_object_delete completing
1.044017792s s3:multi_object_delete op status=0
1.044017792s s3:multi_object_delete http status=200
Note how most of the time here is spend verifying the permissions. Almost an entire second. The actual deletion process doesn’t seem to take any time at all.
Here’s another log, this one from a failed execution which ran into a timeout:
0.000000000s initializing for trans_id = tx00000ce815c8f63c5944a-00671cc609-441e22-homenet
0.000000000s rgw api priority: s3=8 s3website=7
0.000000000s host=s3.example.com
0.000000000s subdomain= domain= in_hosted_domain=0 in_hosted_domain_s3website=0
0.000000000s final domain/bucket subdomain= domain= in_hosted_domain=0 in_hosted_domain_s3website=0 s->info.domain= s->info.request_uri=/mastodon
[...]
0.004000000s s3:multi_object_delete reading permissions
0.004000000s s3:multi_object_delete init op
0.004000000s s3:multi_object_delete verifying op mask
0.004000000s s3:multi_object_delete required_mask= 4 user.op_mask=7
0.004000000s s3:multi_object_delete verifying op permissions
60.060012817s op->ERRORHANDLER: err_no=-2 new_err_no=-2
60.060012817s get_system_obj_state: rctx=0x7fa5c1848690 obj=homenet.rgw.log:script.postrequest. state=0x56036bf760a0 s->prefetch_data=0
60.060012817s cache get: name=homenet.rgw.log++script.postrequest. : hit (negative entry)
60.060012817s s3:multi_object_delete op status=-2
60.060012817s s3:multi_object_delete http status=404
Here, the next log line, NOTICE: call to do_aws4_auth_completion never
appears, instead the operation fails because Mastodon runs into its 60 second
S3 read timeout and closes the connection. In the working call, the next log
line also only appeared after a long delay, almost one second, but it did appear.
Here, nothing seems to be happening.
I had a look at the source code of the RGW as well (yay, open source!).
I was able to find the function which produces the verifying op permissions
log line at line 220 in rgw_process.cc.
That calls verify_permission on the DeleteObjects API implementation,
in rgw_op.cc.
But that was as far as I got. I tried to google around a bit for the names of
the functions I had identified, but the only thing I found was this bug
about a potential deadlock issue. But in the end it also didn’t read like
anything useful.
At this point I pretty much gave up. I toyed a bit with the idea that perhaps there was some issue with the RGW client contacting the MON daemon while checking the permissions, but then realized that this is not Ceph auth, but S3 auth, which is done entirely inside the RGW daemon.
It was quite interesting to rummage through the Ceph RGW codebase, but sadly it did not yield any results.
Updating Ceph
As a last ditch attempt at a fix, I decided to update my baremetal Ceph cluster to v18. That also did not fix the issue, but it was still a good idea to do, considering that v17 has been out of support for a while now.
It works - after a fashion
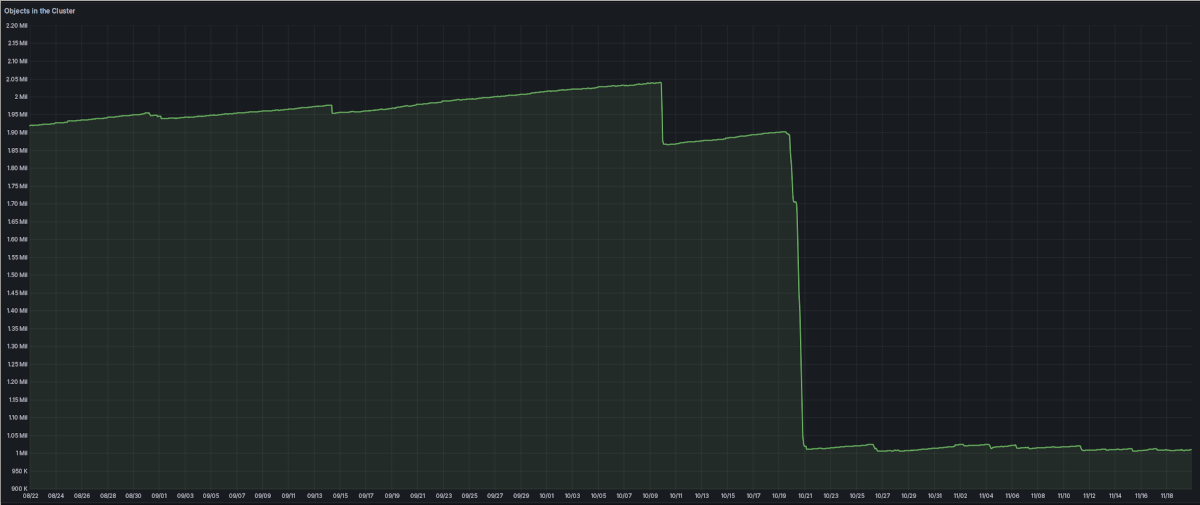
So the end result of all the time I spend on this was a whole lot of “not very much”. But it still did something. Here’s the development of the total number of Ceph objects in the cluster after the big deletion:

The deletions happen unevenly.
As the graph shows, deletion does now work. But it works unevenly. Sometimes, I’m getting no objects deleted at all, with the job failing after it runs out of retries for the first deletion already. And sometimes it successfully runs for hours and deletes 10k objects. I’m happy to see that it works at all, but I’m still a bit disappointed that I wasn’t able to figure out what the actual problem was.
Finally, here is a graph of the stored data in the Ceph pool which houses the Mastodon S3 bucket:

This plot shows the amount of storage used in my HDD backed bulk storage pool, which backs Mastodon’s S3 bucket.
The main thing to note on this plot is the relatively small change. Note that the Y axis goes only from 1.94 TiB to 1.96 TiB. Even the largest drop is below 10 GiB. Compare for example the first larger drop, late on October 26th, on both plots. In the object count plot, this is a reduction of 20k objects. But those only make up for under 10 GiB on the used storage plot.
Conclusion
Quite honestly, even though I was not able to get to the bottom of the issue, I still enjoyed the process. It was a really nice Homelabbing task. I especially enjoyed the trip into the Ceph RGW C++ source code. It doesn’t happen often that I get to use my C++ proficiency in the Homelab. Most things are implemented in Go or web languages.
So how to go forward with this? I’m not quite sure. It’s “good enough” for now,
and at least I’ve learned to keep an eye on it. I’ve also increased the priority
of the task for setting up monitoring of the S3 buckets and their sizes slightly.
The overall object count was a pretty good proxy here, but I’d like to have
the history for specific buckets.
I also want to return here at some point, to really look into Ceph’s RGW, with
the goal of setting up a VM test cluster and trying to reproduce the issue with
a minimal example. Because right now I don’t have anything I could put into a
bug report against Ceph (as noted in the beginning, I’m pretty sure this is an
issue in Ceph, not Mastodon) besides lots of hand waving. And “there’s something
wrong with the RGW’s handling of the DeleteObjects API” just isn’t a useful
bug report.
I’m also still considering writing a feature request towards Mastodon, to
perhaps introduce an env variable to allow switching the Vacuum job from using
the DeleteObjects S3 API to using DELETE requests similar to what tootctl does.
But there again, this doesn’t look like a Mastodon issue to me, and the team
really already has enough things on its plate.