
Wherein I set up cloud-native-pg to supply Postgres clusters in my k8s cluster.
This is part nine of my k8s migration series.
PostgreSQL is currently the only DBMS in my Homelab. My initial plan was to just copy and paste the deployment over from my Nomad setup. But then I was pointed towards CloudNativePG, which is an operator for managing Postgres deployments in Kubernetes.
But before I go into details on CloudNativePG, a short overview of my current setup in Nomad. I’ve got only a single Postgres instance, hosting several databases for a variety of apps. By far the largest DB at the moment is for my Mastodon instance, with something over 1 GB in size. It runs on a CSI volume provided by my Ceph cluster, located on a couple of SSDs. All apps use this one Postgres instance, and there’s no High Availability or failover.
For backups, I’m doing a full pg_dumpall of all the databases, which I pipe
into Restic and back up to an S3 bucket. For new apps, I’m following a simple
playbook of manually creating the database and the DB user from the command line
with psql.
This approach is okayish, but CloudNativePG has one big advantage: It allows declarative creation of Postgres instances. So I won’t have to follow a playbook anymore.
Overview of CloudNativePG
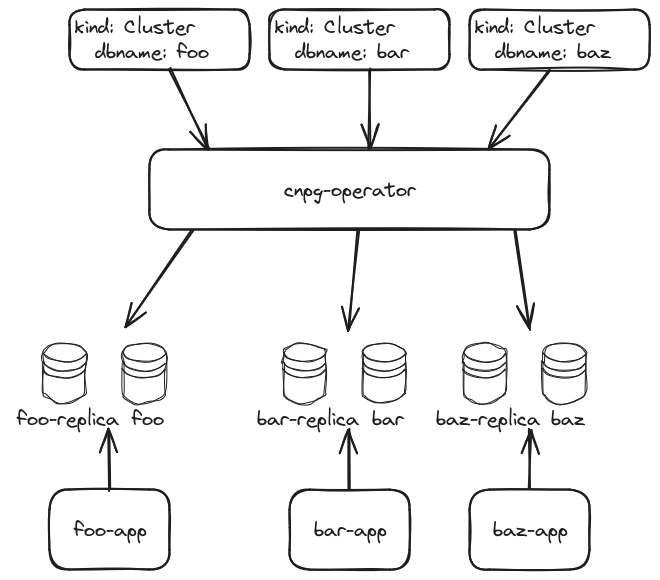
Architecture of CloudNativePG.
The CloudNativePG architecture is centered around the operator. This operator is responsible for creating the database clusters themselves. And these are full Postgres clusters. CloudNativePG only has minimal direct support for multiple databases in a single cluster.
When the operator sees a new Cluster resource, it creates the given number of Postgres Pods. This can range from a single pod, without any High Availability, to a cluster with a single primary and a number of replicas. The replication is entirely build upon Postgres’ own replication features. CloudNativePG only provides the correct configuration, but doesn’t put anything on top of it.
Each new cluster is created with a single database and two users, the
postgres superuser and an application user which only has permissions for the
application database.
When a new cluster is created, the operator also provides a Kubernetes Secret, with the username and password of the application DB user, the name of the Service for that particular cluster as well as a full JDBC string. Applications wanting to use the cluster only need to consume the appropriate keys from the Secret.
In addition to providing the database cluster itself, CloudNativePG also provides a pretty nice backup system as well as easy use of backups created from that data to create fresh clusters when recovery from an incident is necessary.
Those backups can be based on writing to an S3 bucket, or creating volume snapshots from within Kubernetes. In this post, I will concentrate on the S3 method, as that’s what I decided on. No specific reason, besides the fact that I’ve got my other backups in S3 as well, and I already have infrastructure to back those buckets up on separate media.
In the S3 backups, the Write Ahead Logs are constantly streamed to S3. At the
same time, regular backups of the full PGDATA directory are created and
also pushed to the bucket.
But all of this also comes with some downsides, at least from my PoV. The first and foremost one is that CloudNativePG only fully supports one database per Postgres cluster. This is contrary to my current setup with one cluster and many databases. On a certain level, the setup with one database cluster per database/app doesn’t make much sense to me. Postgres is made to support a number of different databases per cluster, not just one. But this “one DB per cluster” has grown out of the Microservice architecture paradigm. And it does have its advantages. E.g. when different apps support different Postgres versions.
But it also comes with some overhead. With a single cluster, I can just throw some HW at it and check occasionally whether I need to add some more. Be this CPU, memory or storage. But with multiple clusters, I need to make that decision for each app. And I need to do it up front, where I don’t have any data to base those decisions on. And there’s a pretty wide gap just in the apps I’m already running. Both Nextcloud and Mastodon put quite some demands on the databases, with the Mastodon DB at over 1 GB in size even for my single-user instance. At the same time, those two apps also put consistent load on the DBs, even when I don’t directly use them. On the other side are things like Keycloak, where the DB comes in at 12 MB, where access only happens when I actually log in somewhere. Making all of these decisions, and making them up front, isn’t that nice compared to just having a single DB instance where I just throw some HW at it occasionally. Now, I have to do that for eight different instances.
Next is the backups. Streaming the WAL to S3 will mean at least some more strain on my S3 infrastructure. And those WALs are not optional. When using an S3 bucket for backups, the WALs are mandatory. But it doesn’t feel like they bring me any benefit. I mean sure, when I actually have an issue and need to restore, it’s going to be nice to be able to do Point in Time restores, instead of having to put in the potentially up to 24h old last backup. There’s also an issue with retention. It’s one-dimensional. I can provide one time window, say 30 days, for which I can restore, but there’s no concept of saying “I want a backup for the last 14 days, each one of the last 6 months, and one year ago”.
But with all of this whining, I’m still a sucker for declarative definitions of my database, so let’s quit the complaining and get to some YAML files. 🤓
Detour: Looking at K8s priority classes
Ah, but before we get to the YAML, I would like to take a rather short detour
to Kubernetes’ PriorityClass.
These priority classes are basically complex wrappers around a number between
-2147483648 and 1000000000. They are priorities used for scheduling by
Kubernetes. If there’s no space left on the cluster, and there’s a Pod with a
higher priority than an already running one, the running Pod will be removed
and the higher priority one will be deployed.
Kubernetes comes with two of those classes by default, system-cluster-critical and
system-node-critical. As an example, most of my Ceph Rook pods have one or
the other of those. My MON Pods, for example, have the node critical class, as
it is not just important that they run somewhere, but it is important that they
run on certain nodes. The same is true for example for my Fluentbit log shippers,
they also should be running on all nodes before absolutely anything else.
For cluster level critical, my example would again be Ceph Rook Pods, namely
the CSI providers. They don’t have to run on specific nodes, but they definitely
have to be running somewhere.
But in my Homelab, there are some additional things which should have priority. The first thing is just critical apps. This would be things like my databases, because so many other services will depend on them, which is why I bring priorities up here. The second special class of services is going to be externally visible services. So for example, it is way more important to me that my Mastodon instance stays up than that my Gitea instance stays up.
As an example, the hl-critical PriorityClass would look like this:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: hl-critical
value: 500000000
globalDefault: false
description: "Priority class for critical Homelab pods"
And now finally to the main event. 🙂
Operator setup
The first part to set up for CloudNativePG is the operator. I’m using the Helm chart for this. There aren’t really that many config options for the Operator itself, so here it is:
config:
data:
INHERITED_LABELS: homelab/*
podLabels:
homelab/part-of: cloud-native-pg
priorityClassName: "hl-critical"
resources:
requests:
cpu: 50m
memory: 100Mi
monitoring:
podMonitorEnabled: false
grafanaDashboard:
create: false
monitoringQueriesConfigMap:
queries: ""
Two interesting things here. The first one is the config.data.INHERITED_LABELS
setting. This defines labels which should be taken from the Cluster manifest
and applied to all resources, like Pods, Secrets and so on, created for that
same cluster. Neat thing to have even auto-generated resources properly labeled.
The second noteworthy config is monitoringQueriesConfigMap.queries. In the
default values of the chart, there are a lot of queries pre-defined. But as
I don’t have any monitoring yet, I disabled them for now.
And that’s it already. Deploying this Helm chart will create a single Pod with the operator, ready to receive Cluster resources for the actual Postgres deployments.
Setting up a CloudNativePG cluster for Keycloak
Before I get to the cluster setups, I would like to rant for a paragraph. I don’t actually have any app on the cluster which needs Postgres yet. But I still wanted to test CloudNativePG before moving on to that first app. I wanted something really simple, perhaps even something which produces some test data on a button press, with a small web frontend to read the data again, to verify that DB restores worked properly. So I googled, with something like “kubernetes postgres simple app” or “simple postgres test app”. And I got zero results. None. All I got were boatloads of articles on how to setup Postgres on Kubernetes, or how to write a simple app using Postgres with language/framework X. And I’m pretty sure that something like what I want exists. Probably in dozens of varieties, even. But Google would not surface those apps. I tried a lot of permutations of the above queries. Nothing.
But I got lucky, and Rachel pointed me towards Keycloak. It has the advantage that it only needs Postgres as a dependency, so it was relatively easy to set up. Plus, I’m already running a Keycloak instance on Nomad, so I’m familiar with it already. And creation of new users is sufficiently close to “create database records on the press of a button” for my needs. Thanks Rachel. 🙂
Basic cluster and Keycloak setup
Yes, this is where we finally get to see a Postgres Pod enter the story. 😅
So as I’ve mentioned multiple times before, the Operator is fed with Cluster type resources and then spawns the appropriate number of Postgres Pods, configures replication and generates a secret for use by the app.
My Keycloak test cluster looks like this:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: keycloak-pg-cluster
labels:
homelab/part-of: keycloak-test
spec:
instances: 2
bootstrap:
initdb:
database: keycloak
owner: keycloak
resources:
requests:
memory: 128Mi
cpu: 100m
postgresql:
parameters:
max_connections: "200"
shared_buffers: "32MB"
effective_cache_size: "96MB"
maintenance_work_mem: "8MB"
checkpoint_completion_target: "0.9"
wal_buffers: "983kB"
default_statistics_target: "100"
random_page_cost: "1.1"
effective_io_concurrency: "300"
work_mem: "81kB"
huge_pages: "off"
max_wal_size: "1GB"
storage:
size: 2Gi
storageClass: rbd-fast
Because I set the INHERITED_LABELS config in the operator to homelab/*,
all resources created for this cluster will get the label homelab/part-of: keycloak-test.
The metadata.name is significant here, as it will become part of the Pod names
as well as the path for backups, once we get to them. The instances config
determines the replication. There needs to be at least one instance, the primary.
All additional instances are replicas. CloudNativePG also supports more involved
configs, but I’m keeping it simple here, with a single primary and a single
replica.
The bootstrap section defines how the database is initially created. The
initdb method I’m using here creates an empty database. You can also create
the cluster from another cluster, either from a running cluster, where the new
cluster will use the streaming replication protocol, or from a backup, when the
previous cluster doesn’t exist anymore. I intend to give the streaming replication
approach a try when I start migrating services using Postgres from my Nomad cluster.
Perhaps I can skip manual pg_dump backups and restores this way.
I will show restoration of a cluster from another cluster’s backups in a later
section.
The postgresql.parameters were initialized via pgtune.
I never tuned my databases before, and I’m curious what impact this will have
on DBs with higher load, like my Mastodon DB.
Last but not least, I’m telling CloudNativePG to use my SSD-backed rbd-fast
StorageClass and provide a 2GB volume.
Once I deploy this manifest, the Operator gets to work. It will first create a Postgres Pod for the primary. These Pods use special CloudNativePG images, not the default Postgres ones. Once that’s set up, it will create a second pod, as a replica.
In the Postgres instances, multiple users will be created. First, the postgres
superuser. This user will not be made available anywhere and is only for internal
use. But another user, in this case called keycloak as configured in
spec.bootstrap.initdb.owner will be created. This user is intended for use
by the app. Its credentials will be put into a Secret called $CLUSTERNAME-app,
in this particular example keycloak-pg-cluster-app. This secret has the
following content:
data:
dbname: keycloak
host: keycloak-pg-cluster-rw
jdbc-uri: jdbc:postgresql://keycloak-pg-cluster-rw:5432/keycloak?password=6yitavmmX1OP5lDuRC1iL3epmujnWczqKNnnS7lM7Ez4CLGqzqYb1ikTmWGo5EyJ&user=keycloak
password: 6yitavmmX1OP5lDuRC1iL3epmujnWczqKNnnS7lM7Ez4CLGqzqYb1ikTmWGo5EyJ
pgpass: keycloak-pg-cluster-rw:5432:keycloak:keycloak:6yitavmmX1OP5lDuRC1iL3epmujnWczqKNnnS7lM7Ez4CLGqzqYb1ikTmWGo5EyJ\n
port: 5432
uri: postgresql://keycloak:6yitavmmX1OP5lDuRC1iL3epmujnWczqKNnnS7lM7Ez4CLGqzqYb1ikTmWGo5EyJ@keycloak-pg-cluster-rw:5432/keycloak
user: keycloak
username: keycloak
This secret contains all the information a client needs to connect to the DB
cluster. The given host: keycloak-pg-cluster-rw is a service CloudNativePG
creates, and which points to the primary of the cluster. In addition to this
service, CloudNativePG also creates keyloak-pg-cluster-r and keycloak-pg-cluster-ro
services, which point to both the primary and replicas or the replica only,
respectively. This can be used when there are some read-only apps using the
database.
Let me show you a quick example of how to connect to the Cluster, with Keycloak as an example.
DO NOT USE THIS IN PROD!
spec:
template:
metadata:
labels:
app: keycloak
homelab/part-of: keycloak-test
spec:
containers:
- image: quay.io/keycloak/keycloak:23.0.7
args: ["start-dev"]
name: keycloak
env:
- name: KC_DB
value: "postgres"
- name: KC_DB_URL_HOST
valueFrom:
secretKeyRef:
name: keycloak-pg-cluster-app
key: host
- name: KC_DB_URL_PORT
valueFrom:
secretKeyRef:
name: keycloak-pg-cluster-app
key: port
- name: KC_DB_URL_DATABASE
valueFrom:
secretKeyRef:
name: keycloak-pg-cluster-app
key: dbname
- name: KC_DB_USERNAME
valueFrom:
secretKeyRef:
name: keycloak-pg-cluster-app
key: user
- name: KC_DB_PASSWORD
valueFrom:
secretKeyRef:
name: keycloak-pg-cluster-app
key: password
This shows how to use valueFrom.secretKeyRef to get the database connection
details from the Secret which was created by CloudNativePG.
There’s also one important configuration needed when you’re using NetworkPolicy to secure the Namespace where the cluster is created. This NetworkPolicy needs to allow the CloudNativePG operator to access the cluster pods. In a CiliumNetworkPolicy, it looks like this:
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "keycloak-pg-cluster-allow-operator-ingress"
spec:
endpointSelector:
matchLabels:
cnpg.io/cluster: keycloak-pg-cluster
ingress:
- fromEndpoints:
- matchLabels:
io.kubernetes.pod.namespace: cnpg-operator
app.kubernetes.io/name: cloudnative-pg
Here, I’m using the fact that CloudNativePG adds a label with the Cluster name to each pod to allow access only to the DB pods. An example for a Kubernetes NetworkPolicy can be found here.
Before continuing to the backup configuration, here is a warning which worried me, after creating my first cluster:
"Warning: mismatch architecture between controller and instances. This is an unsupported configuration."
That warning got my intention - I’m running most of my workloads on Raspberry Pi 4, but I also have some x86 machines, just in case I end up with a workload that doesn’t support AArch64. The really frustrating thing at this point was that, yet again, Google utterly deserted me. It looked like there were zero hits for the warning message. Luckily, after some searching of the CloudNativePG repo on GitHub, I found this issue. That then brought me to the realization that multi-arch clusters are currently only a problem when in-place updates for the manager running in the Postgres containers are needed. But I did not enable those anyway.
Adding backups
Next up: Preventing disaster. For backups, I went with the S3 bucket based
backups, instead of the volume snapshots method. This backup method has two
pieces. The first one is continuous backups of the WAL, and the second is a
regular full backup of the PGDATA directory. More info on the backup methods
can be found in the CloudNativePG docs.
But I hit a snag with my overall setup here. As described in a previous article, I’ve got a second stage in my backup where I download all of the backup buckets onto an external HDD. So I need to provide access to the S3 user used for those external HDD backups to all backup buckets. This includes the Postgres backup bucket. But sadly, Ceph Rook’s Object Bucket Claim does not support setting a policy on the new bucket. So instead of using OBCs, I created a single bucket in Ansible. Then I will use Rook’s CephObjectStoreUser to create the S3 user, separately for each Postgres cluster/Namespace. This will generate a Secret with the necessary credentials to access the bucket, which I can then use to configure the CloudNativePG backup.
Here again, I’m pretty happy with what I was able to do in the Ansible playbook. Here is the play which creates my backup buckets, together with the task for the Postgres backup bucket:
- hosts: candc
name: Play for creating the backup buckets
tags:
- backup
vars:
s3_access: "S3 access key id here"
s3_secret: "S3 secret access key here"
cnpg_backup_users:
- keycloak
tasks:
- name: Create cnpg backup bucket
tags:
- backup
- cnpg
amazon.aws.s3_bucket:
name: backup-cnpg
access_key: "{{ s3_access }}"
secret_key: "{{ s3_secret }}"
ceph: true
endpoint_url: https://s3.example.com
state: present
policy: "{{ lookup('ansible.builtin.template','bucket-policies/backup-cnpg.json.template') }}"
Important to note here is the cnpg_backup_users list, which contains all the
users for the CloudNativePG clusters to be backed up. Right now, only the Keycloak
test setup. Here is the bucket policy referenced in the policy key:
{
"Version": "2012-10-17",
"Statement": [
{% for user in cnpg_backup_users %}
{
"Action": [
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObject",
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::backup-cnpg/{{ user }}-pg-cluster/*",
"arn:aws:s3:::backup-cnpg/{{ user }}-pg-cluster",
"arn:aws:s3:::backup-cnpg"
],
"Principal": {
"AWS": [
"arn:aws:iam:::user/cnpg-backup-{{ user }}"
]
}
},
{% endfor %}
{
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::backup-cnpg/*",
"arn:aws:s3:::backup-cnpg"
],
"Principal": {
"AWS": [
"arn:aws:iam:::user/extern-backups-s3"
]
}
}
]
}
This policy grants access to each Db backup user only for certain subdirectories,
namely $USERNAME-pg-cluster/, as by default, CloudNativePG puts the backups
of different clusters into subdirectories with those Cluster’s metadata.name.
The CloudNativePG backup config itself then looks like this:
backup:
barmanObjectStore:
endpointURL: http://rook-ceph-rgw-rgw-bulk.rook-cluster.svc:80
destinationPath: "s3://backup-cnpg/"
s3Credentials:
accessKeyId:
name: rook-ceph-object-user-rgw-bulk-cnpg-backup-keycloak
key: AccessKey
secretAccessKey:
name: rook-ceph-object-user-rgw-bulk-cnpg-backup-keycloak
key: SecretKey
retentionPolicy: "90d"
This is put under spec in the Cluster manifest. This config tells
CloudNativePG how to access the S3 backup bucket, and that all data should be
retained for 90 days. This is going to be true for both, WALs and full PGDATA
backups.
After this update is made to the Cluster manifest, you might see this error message in the logs:
"error":"while getting secret rook-ceph-object-user-rgw-bulk-cnpg-backup-keycloak: secrets \"rook-ceph-object-use
r-rgw-bulk-cnpg-backup-keycloak\" is forbidden: User \"system:serviceaccount:testsetup:keycloak-pg-cluster\" cannot get resource \"secrets\" in API group \"\" in the namespace \"testsetup\""
Don’t be alarmed by it, it just seemed to be a transient error which went away on its own.
After a couple of moments, CloudNativePG should start streaming the WALs to the S3 bucket already. For this example, the path in the bucket looks like this:
s3://backup-cnpg/keycloak-pg-cluster/wals/
I like the fact that CloudNativePG doesn’t just assume that the cluster has the entire bucket to itself, but instead puts the data into a directory under the root, allowing me to put the backups of all the clusters into the same bucket.
But the WALs are only part of the backup. The second part is the full PGDATA
backup, and that’s done via a ScheduledBackup:
apiVersion: postgresql.cnpg.io/v1
kind: ScheduledBackup
metadata:
name: test-backup
spec:
method: barmanObjectStore
immediate: true
schedule: "0 0 0 * * *"
backupOwnerReference: self
cluster:
name: keycloak-pg-cluster
This runs a backup every day at exactly midnight. The immediate: true config
tells CloudNativePG to make a backup immediately. This is another one of those
nice little features, avoiding the typical futzing with the schedule to make
it start a backup in five minutes for testing.
Recovery
And finally, let’s have a look at how to use the previously created backups to create a new cluster, as an example of a post-incidence recovery operation.
It’s important here that while I deleted the old Cluster completely, I left the S3 bucket user and its associated secret. That’s needed so CloudNativePG can use those credentials to get at the data from the old cluster.
Recovery itself is pretty straightforward. Instead of adding a bootstrap.initdb
key, the bootstrap.recovery key is used, like this:
spec:
instances: 2
bootstrap:
recovery:
database: keycloak
owner: keycloak
source: keycloak-pg-cluster
The database and owner keys need to be set. Without them, CloudNativePG will
read in the old database from the backups, but it will also create the default
app database, and create new Secrets for that DB, instead of the restored keycloak
DB.
The source: keycloak-pg-cluster references an entry in the externalClusters
section, which looks almost like the backup: section of the original cluster’s
config:
externalClusters:
- name: keycloak-pg-cluster
barmanObjectStore:
endpointURL: http://rook-ceph-rgw-rgw-bulk.rook-cluster.svc:80
destinationPath: "s3://backup-cnpg/"
s3Credentials:
accessKeyId:
name: rook-ceph-object-user-rgw-bulk-cnpg-backup-keycloak
key: AccessKey
secretAccessKey:
name: rook-ceph-object-user-rgw-bulk-cnpg-backup-keycloak
key: SecretKey
Here again, CloudNativePG will assume that the backups are stored under the
name of the cluster in the bucket. The restore with this config worked without
issue and after it was done, I saw my previously created test realm and users
again in Keycloak.
Conclusion
Phew. Okay. This setup took way longer than I had initially thought, mostly because I almost jumped ship after the initial research and finding out that it doesn’t really support multi-DB clusters. And also because I ended up deciding that I would like to get hands on with the recovery procedure before I actually need it.
One of the potential downsides is that, just by virtue of running multiple clusters, it will very likely need more resources than my current single-cluster setup. I’m still not too happy with the backup, I would have preferred something closer to restic, at least with deduplication. I will probably at least enable compression by default at some point, to save on storage space on the S3 bucket.
Then again, let’s be honest here: Complexity is sort of the goal. 🤓