This is the next post in the Current Homelab series, where I give an overview of what my lab is currently looking like. This time, I will be talking about my storage layer, which is mostly made up of Ceph.
I chose Ceph around spring 2021, when I decided to go from a baremetal+docker-compose setup to a VM based setup with LXD. At the time, my main storage consisted of a pair of WD Red 4TB disks for my main storage requirements, and a 60GB crucial SATA SSD for my server’s root FS. While going through the LXD docs, I saw that it supported something called “Ceph RBD” for its VM volumes.
After some research into Ceph, I was hooked. The main driver for me: It provides all current types of storage from a single pool of disks, and it had good permission management on top. I could take storage from the same disk for RBDs, Ceph’s block device provider, for my VM root disks. CephFS, again using the same storage pool, would provide me with a good POSIX compatible file system capable of being used at the same time between multiple hosts. And finally, the RadosGW would provide me with an S3 API for those of my services which were able to use it.
In addition, I had already decided to migrate my system to Nomad. Nomad supports the CSI spec (way better now than it did back then) and I wanted to use that for my container’s data volumes.
Plus, it was complicated (or rather, it looked complicated to me then 😉). So of course I had to set it up in my homelab. 😅
What exactly is Ceph?
To go with Ceph’s own words:
Ceph is an open-source, distributed storage system.
Right now, I believe its main developer is Red Hat, where it is packaged as “Red Hat Enterprise Storage”. But it also has a lot of other contributors. The virtualization OS Proxmox for example uses Ceph as one of their storage layers.
One word of caution: Don’t use it on Arch. In Arch typical fashion, you might start using it, and then it gets incredibly outdated in their packages, and then it’s gone. Remember: There’s a reason lots of people love to use it as their OS of choice - and nearly nobody actually uses it for anything productive.
So what is Ceph? At the core, it is a set of Daemons (these days deployed in Docker containers) running on a set of hosts.
There are three types of important daemons in every cluster:
- Ceph MON daemons: They are the “brain” of the operation, coordinating the cluster. We can liken it to a “control plane”.
- Ceph MGR daemons: These daemons “manage” the cluster deployment. They provide a very nice dashboard+web interface and control the orchestrator
- Ceph OSD daemons: These are the actual storage services. Normally, there is one daemon per disk in the cluster
A good overview of Ceph’s architecture can be found here.
In principle, it works something like this: Every piece of data which is written to the cluster - whether it’s coming in via an RBD, CephFS or S3, is written to a RADOS (Reliable, Autonomous, Distributed Object Store) object. These objects, in turn, are written to placement groups, which in turn are written to OSDs.
The MON daemons are the first piece of a Ceph cluster contacted by any client. They contain what’s called the “cluster map” - information on what the cluster is currently looking like. They also forward info about other daemon’s IPs and ports, so that clients only need the IPs of the MON daemons.
But that’s where the job of the MON daemons (relating to clients) ends. MON daemons do not play any part at all in the actual data transfer. For that, the client directly contacts one of the OSDs which holds the required piece of data. This is Ceph’s main scalability mechanism - instead of going through a central daemon, clients contact the storage daemons directly. This avoids both, a perf bottleneck and a single point of failure. That’s why MONs hand the cluster map to clients. With those maps, the clients can compute which OSD a specific piece of data is located on. The algorithm used to compute data placement - both, in OSD daemons when writing a new piece of data, and in clients when looking for a piece of data - is called “CRUSH”, the “Controllable, Scalable, Decentralized placement of replicated data”.
In addition to these basic daemons, Ceph also supports some additional daemons for specific tasks. I will go into detail later, but for completeness’ sake:
- Rados Gateway daemons provide an S3 (and Swift) compatible API
- MDS daemons are needed for CephFS to work (they store/handle file metadata and locking)
- NFS: Ceph provides the ability to export Ceph storage as NFS via NFS Ganesha
- If you don’t have any monitoring yet, Ceph can deploy Prometheus/Grafana in the cluster
Data organization
As mentioned above, all data in a Ceph cluster is owned by an “OSD” daemon - an “Object Storage Device” daemon. These daemons normally own an entire disk, controlled via LVM2. If necessary, you can also only assign a LVM partition to the daemon. But for performance reasons, it is preferred to assign an entire disk to the OSD.
An OSD daemon normally requires storage for multiple pieces of data. The first one is the actual data to be stored. But the daemon also makes use of a WAL and a DB for indexing the data. All three of these datasets can be stored on the same disk - this is the default, and also what I’m doing to make the most out of my available storage. But you can also go for a different approach, for example with the WAL on another device entirely. Especially for HDDs, this will improve performance considerably. With both the WAL and the data itself on the same HDD, the max write speed you will reach is around 60 MByte/s. Because the OSD needs to write both, the WAL and the actual data to the same disk. When the WAL is stored on another device, you will get your full write speed. I will go into a bit more detail on why I decided against that later.
After a new OSD has been created, the CRUSH algorithm comes into play. Each OSD can be assigned a class - by default, these are just the disk types, SSD or HDD. These can be used in CRUSH rules. CRUSH rules in turn describe how the data is stored in the cluster. In my case, I didn’t do too much fancy configuration here. I only have two different rules. One for HDDs, one for SSDs. The major decision for CRUSH rules is whether you would like to use erasure coding or simple replication. I decided for simple replication, which makes sure that each piece of data is written to multiple OSDs, and with that multiple disks. In my setup, the replication factor is two - which is similar to RAID1. Every piece of data is written to the cluster twice. Quite frankly, the reason I went with replication was that I at least could understand the approach and the failure modes. 😉
The next step is creating different “Pools”. These are storage abstractions
mostly useful for access control. I’ve got two base pools, homenet-base-fast
containing only SSDs and homenet-base-bulk, containing only HDDs. Then
I’m using several additional pools for separation of concerns, e.g. one SSD
only pool for VM’s root volumes. The main effect this has is that I can do
better access control on the pool level than when just putting everything into
the same pool.
Once you’ve setup pools, you can use them for anything - S3, block devices and CephFS, at the same time.
For example, when creating an RBD volume you provide the image name, but also the pool name where the image should be created.
Cephadm: The Orchestrator
Now onto how a Ceph cluster is actually set up. In the past, this was done via direct baremetal installs with Ansible. But since a couple of releases ago, all deployment related actions are done with a tool called cephadm by default. This is a reasonably simple script which can deploy and manage Docker containers and their accompanying Systemd units.
A host to be used with Ceph only needs a couple of things installed:
- Docker or Podman
- systemd
- An NTP client
- cephadm (can just be downloaded with e.g.
wgetas it is only a script)
And that’s it. Then a simple ceph orch host add HOSTNAME IP will initialize it
and make it known to the cluster orchestrator. Then daemons can be deployed with
ceph orch apply....
For example, if you’ve got a running cluster, and you’re adding the new host
freshdisk with an unused SSD at /dev/sdb, the following commands will add
that unused disk to your cluster’s capacity:
ceph orch host add freshdisk 10.0.0.42
ceph orch daemon add osd "freshdisk:/dev/sdb"
And that’s it already. Isn’t that beautiful? 😄
The orchestrator can also be used for other things, like looking at the current status of all the cluster daemons:
ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
mds.homenet-fs.geb.jsczvb geb running (15h) 5m ago 19M 174M - 16.2.10 894500bd46d8 5f24c8b16ff2
mds.homenet-fs.neper.hsozsd neper running (15h) 74s ago 7d 25.4M - 16.2.10 894500bd46d8 481d92500a33
mgr.neper.rudmha neper *:8443,9283 running (15h) 74s ago 7d 426M - 16.2.10 894500bd46d8 e5b454d491da
mgr.nut.xkdana nut *:8443,9283 running (15h) 5m ago 6d 587M - 16.2.10 894500bd46d8 7b0312baae1e
mon.baal baal running (15h) 5m ago 8d 934M 2048M 16.2.10 37f942a69a5c 0cb251b98f47
mon.beset beset running (21h) 5m ago 8d 938M 2048M 16.2.10 37f942a69a5c fbea8a9de708
mon.buchis buchis running (21h) 5m ago 8d 935M 2048M 16.2.10 37f942a69a5c ae0268da0793
nfs.hn-nfs.0.2.neper.bxpxxu neper *:2049 running (15h) 74s ago 15h 73.0M - 3.5 894500bd46d8 202f56311c86
osd.0 nut running (15h) 5m ago 19M 2457M 4096M 16.2.10 894500bd46d8 d5007c723c51
osd.1 geb running (15h) 5m ago 19M 2698M 4096M 16.2.10 894500bd46d8 d72e54c8258f
osd.2 nut running (15h) 5m ago 19M 4790M 4096M 16.2.10 894500bd46d8 424b6acd8c98
osd.3 geb running (15h) 5m ago 19M 5099M 4096M 16.2.10 894500bd46d8 09c3451810fd
osd.4 neper running (15h) 74s ago 9d 3922M 4096M 16.2.10 894500bd46d8 2f73877ca52e
osd.5 neper running (15h) 74s ago 9d 5682M 4096M 16.2.10 894500bd46d8 2708af5a1fab
rgw.homenet.homenet.geb.qkcblq geb *:80 running (15h) 5m ago 16M 229M - 16.2.10 894500bd46d8 3686fe149ac6
rgw.homenet.homenet.neper.amnqro neper *:80 running (15h) 74s ago 7d 209M - 16.2.10 894500bd46d8 b33b760f9082
You can also stop entire services, e.g. ceph orch stop rgw.homenet.homenet will
stop all of my RGWs. Another example is the version upgrade. The orchestrator
will, one after another, stop the daemons, update the Docker image and restart
the daemon. It makes sure to never update more than one daemon from any specific
service to make sure the entire cluster stays up.
The Web UI
In addition to the command line interface, Ceph also provides a comprehensive Web UI. It allows executing almost all actions you might want to use, if you don’t like CLIs.
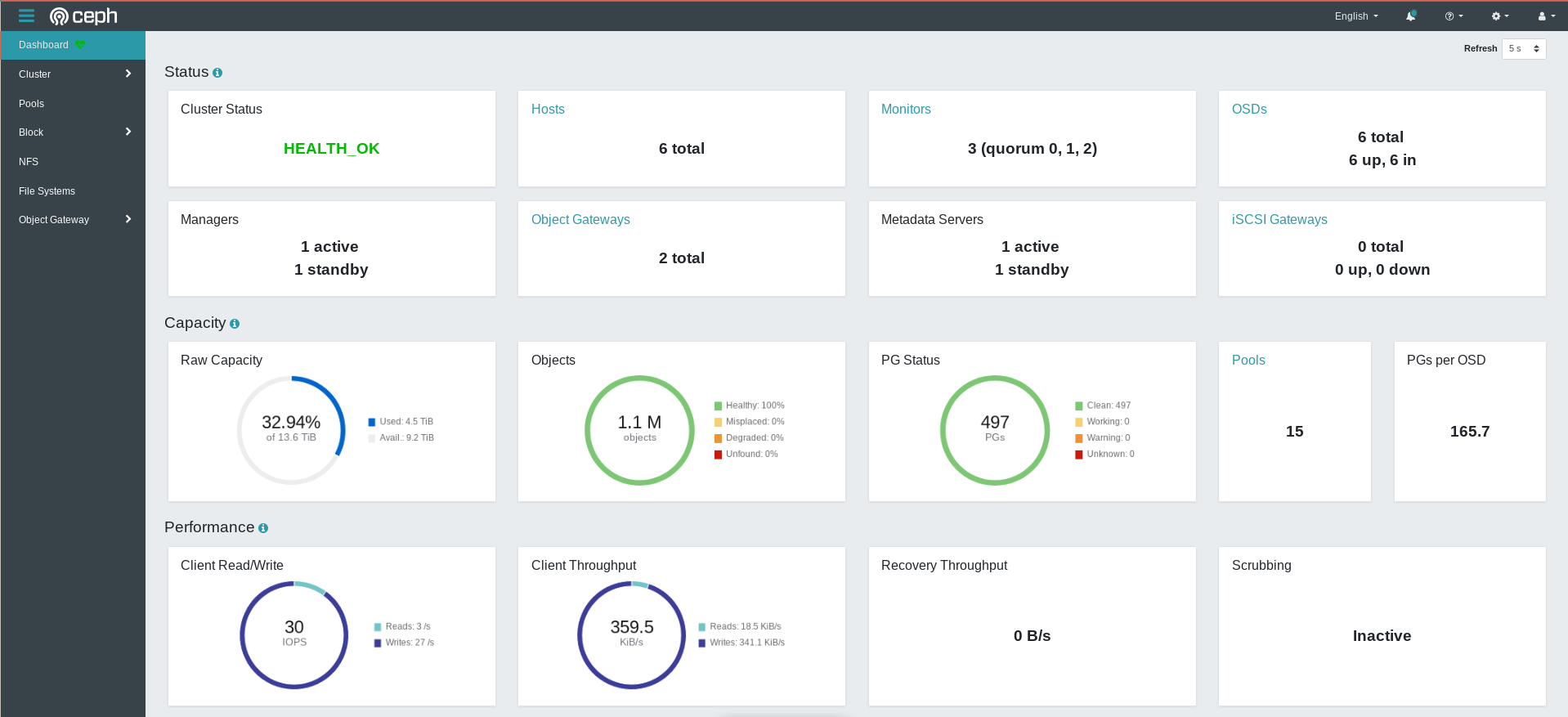
Ceph in the Homelab
So why would you run Ceph in the Homelab? I’m afraid I can’t provide a comparison to ZFS, which is the other main Homelab storage solution, as I never used it.
But here are a couple of points for and against Ceph at home. First, it’s all commodity - you don’t need any special HW. You can also mix and match. Have an old 500 GB HDD laying around that’s still good? No problem throw it into your cluster together with 1 TB, 6TB, 4 TB etc disks. Ceph simply doesn’t care. To a certain extend, at least. If you’ve got a replication factor of two, and you combine one 6TB disk with one 500 GB disk - you will have a bad time, of course. But if you have two 1TB disks and add a third 60GB disk - you will still benefit from (a bit) more space.
Easier expansion is another plus. You don’t necessarily have to find another space for your new HDD in your current server - you can just add a new server.
Then there’s the fact of having the ability to get all three types of storage from exactly the same disk. No thinking about where to put the datadir for MinIO anymore, or resizing disks to fit another VM root disk into your LVM pool.
So why wouldn’t you use Ceph? First of all, I would advise against running it on only a single node. Its standard upgrade mechanism depends on the fact that you’ve got multiple MGR daemons on different hosts. It does work - I did it for a time, but it’s not too much fun. When you take down that single machine, your entire storage is gone.
You should also consider what I/O you’re expecting. Ceph is completely network based. Not only do the clients need to contact the OSDs for a write operation, but the OSDs also need to contact other OSDs for replication. I’ve got a 1 Gbps network in my lab at the moment. That means I can at most transfer about 125 MByte/s. That’s just a single commodity HDD worth of transfer. And it is far below what current SATA SSDs, let alone NVMe SSDs, can do. That’s also the reason I never bothered with NVMe disks in my Ceph cluster. But quite honestly: I don’t really see this as any sort of problem in my cluster. The average throughput is below 1 MByte/s.
One more point is the RAM consumption. Every OSD consumes at least 4GB of memory by default. That means for each disk in your Ceph cluster, you need 4GB of RAM. This becomes problematic when trying to run a Ceph cluster on e.g. Raspberry Pis.
Finally, one big downside I see with Ceph’s “cluster of commodity HW” approach, specifically in the Homelab: Physical space. I’m living in a nice apartment, but I don’t have a separate space for my servers. So with too many physical machines, the space gets really cluttered. You have to be able to place those Ceph nodes somewhere. I don’t mind too much, but especially if you’re not living alone, you might have some restrictions on how many machines you can strew all over the place. 😉
My Ceph setup
Before I give a short description of my setup, let me emphasize one thing: It changed a lot, in the beginning! And it was always the same cluster, with the same data. Ceph handled all of those migrations without a single hiccup.
My Ceph journey looked like this:
- Initial setup baremetal on my x86 server with 2x HDDs The OS here was Arch (Do not recommend!). Moved away from this deployment because I wanted to use the storage for services which were autostarted at boot, and this produced timing problems.
- A single LXD VM. Here, I slowly migrated the Daemons one by one from the baremetal host to the VM. Sure, I paid a hefty price because all of the data had to be copied to the “new” disk in the VM - but it worked flawlessly. Here I also added 2x SSDs for faster storage
- Multiple LXD VMs. This was mostly to be able to comfortably run multiple instances of e.g. MON and MGR daemons.
- Addition of one more HDD and SSD connected to a Raspberry Pi CM4 with a very very jank Raspberry Pi IO Board PCIe x1 slot -> PCIe to SATA card setup. I ran this as a testing ground for about a year, and it was very stable. But due to the 8GB RAM ceiling on the Pi, I wasn’t able to provide the full 4GB to both OSDs. That’s why I finally canned the plan of using Pis as my storage daemons.
- Switching the disks from the Pi to an Odroid H3. More juice, and more important, more RAM
Through all of this, I destroyed and recreated daemons quite often. In the most recent migration, from the Pi to the Hardkernel, I was able to capture a lot of metrics:
- The limiting factor for the migration was not CPU or even storage speed, but network speed. With the 1 Gbps I have, I was barely able to saturate a single HDD. But Ceph was perfectly able to use every last bit of those 1 Gbps.
- You do not get your HDDs full write speed - instead you get around half, as you need to write both, the WAL and the actual data.
- During the whole time, the Pi’s CPU was not fully loaded
When it comes to Linux distributions, I would like to argue against Arch. Ceph just isn’t in there anymore. But I’ve had good experience with both Debian and Ubuntu, there are packages available for both.
Taking the points above, my next upgrade for general Homelab perf improvements might be 2.5 Gbps Ethernet. Even though at this point I might just want to go 10 Gbps, at least between my Ceph nodes.
My next change for the storage area is going to be disabling my last two Ceph VMs, and migrating them to Hardkernel H3 as well. I’m constantly frustrated in my search for good Ceph node HW. On the one hand, I don’t actually need much CPU. I’m pretty sure the Pi did pretty well where compute was concerned. But I do need lots of RAM. And lots of SATA connectors. But I would also like to have low power consumption. Sadly, the low power retail CPU space is pretty bare, at least right now. Even the low power CPUs with 35W TDP are too much. But anything smaller gets into bespoke machines with soldiered CPU and RAM in bespoke form factors and enclosures. With a single SATA port, if you are that lucky. And for some reason the ITX board space is just weird and expensive.
So for now, the Odroid H3 will serve me well, but I would have wished that I could decide on a proper board+CPU.
So what’s your opinion on Homelab storage? I would especially love to read a similar article like this one here, but about ZFS, as I have zero experience with it.